Dirichlet's Theorem on Arithmetic Progressions
Good evening, contestants.
If a and d are relatively prime positive integers,
the arithmetic sequence beginning with a
and increasing by d, i.e.,
a,
a + d,
a + 2d,
a + 3d,
a + 4d,
...,
contains infinitely many prime numbers.
This fact is known as Dirichlet's Theorem on Arithmetic Progressions,
which had been conjectured by Johann Carl Friedrich Gauss (1777 - 1855)
and was proved by Johann Peter Gustav Lejeune Dirichlet (1805 - 1859)
in 1837.
For example,
the arithmetic sequence beginning with 2 and increasing by 3,
i.e.,
2,
5,
8,
11,
14,
17,
20,
23,
26,
29,
32,
35,
38,
41,
44,
47,
50,
53,
56,
59,
62,
65,
68,
71,
74,
77,
80,
83,
86,
89,
92,
95,
98,
...
,
contains infinitely many prime numbers
2,
5,
11,
17,
23,
29,
41,
47,
53,
59,
71,
83,
89,
...
.
Your mission, should you decide to accept it,
is to write a program to find
the nth prime number in this arithmetic sequence
for given positive integers a, d, and n.
As always, should you or any of your team be tired or confused,
the secretary disavow any knowledge of your actions.
This judge system will self-terminate in three hours.
Good luck!
Input
The input is a sequence of datasets.
A dataset is a line containing three positive integers
a, d, and n separated by a space.
a and d are relatively prime.
You may assume a <= 9307, d <= 346,
and n <= 210.
The end of the input is indicated by a line
containing three zeros separated by a space.
It is not a dataset.
Output
The output should be composed of
as many lines as the number of the input datasets.
Each line should contain a single integer
and should never contain extra characters.
The output integer corresponding to
a dataset a, d, n should be
the nth
prime number among those contained
in the arithmetic sequence beginning with a
and increasing by d.
FYI, it is known that the result is always less than
106 (one million)
under this input condition.
Sample Input
367 186 151
179 10 203
271 37 39
103 230 1
27 104 185
253 50 85
1 1 1
9075 337 210
307 24 79
331 221 177
259 170 40
269 58 102
0 0 0
Output for the Sample Input
92809
6709
12037
103
93523
14503
2
899429
5107
412717
22699
25673
Organize Your Train part II
RJ Freight, a Japanese railroad company for freight operations
has recently constructed exchange lines at Hazawa, Yokohama.
The layout of the lines is shown in Figure B-1.
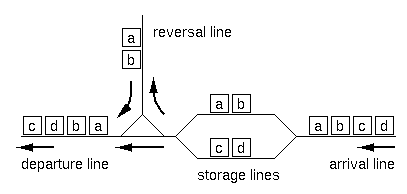
Figure B-1: Layout of the exchange lines
A freight train consists of 2 to 72 freight cars. There are 26
types of freight cars, which are denoted by 26 lowercase letters
from "a" to "z". The cars of the same type are indistinguishable from
each other, and each car's direction doesn't matter either.
Thus, a string of lowercase letters of length 2 to 72 is sufficient
to completely express the configuration of a train.
Upon arrival at the exchange lines, a train is divided into two
sub-trains at an arbitrary position (prior to entering the
storage lines). Each of the sub-trains may have its direction
reversed (using the reversal line). Finally, the two sub-trains
are connected in either order to form the final configuration.
Note that the reversal operation is optional for each of the
sub-trains.
For example, if the arrival configuration is "abcd", the train
is split into two sub-trains of either 3:1, 2:2 or 1:3 cars.
For each of the splitting, possible final configurations are
as follows ("+" indicates final concatenation position):
[3:1]
abc+d cba+d d+abc d+cba
[2:2]
ab+cd ab+dc ba+cd ba+dc cd+ab cd+ba dc+ab dc+ba
[1:3]
a+bcd a+dcb bcd+a dcb+a
Excluding duplicates, 12 distinct configurations are possible.
Given an arrival configuration, answer
the number of distinct configurations which can be
constructed using the exchange lines described above.
Input
The entire input looks like the following.
the number of datasets = m
1st dataset
2nd dataset
...
m-th dataset
Each dataset represents an arriving train, and is a string of
2 to 72 lowercase letters in an input line.
Output
For each dataset, output the number of possible train configurations
in a line. No other characters should appear in the output.
Sample Input
Output for the Sample Input
Hexerpents of Hexwamp
Hexwamp is a strange swamp, paved with regular hexagonal dimples.
Hexerpents crawling in this area are serpents adapted to the
environment, consisting of a chain of regular hexagonal sections. Each
section fits in one dimple.
Hexerpents crawl moving some of their sections from the dimples they
are in to adjacent ones. To avoid breaking their bodies, sections
that are adjacent to each other before the move should also be
adjacent after the move. When one section moves, sections adjacent to
it support the move, and thus they cannot move at that time. Any
number of sections, as far as no two of them are adjacent to each
other, can move at the same time.
You can easily find that a hexerpent can move its sections at its
either end to only up to two dimples, and can move intermediate
sections to only one dimple, if any.
For example, without any obstacles, a hexerpent can crawl forward
twisting its body as shown in Figure C-1, left to right. In this
figure, the serpent moves four of its eight sections at a time, and
moves its body forward by one dimple unit after four steps of moves.
Actually, they are much better in crawling sideways, like sidewinders.
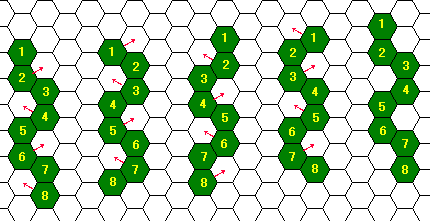
Figure C-1: Crawling forward
Their skin is so sticky that if two sections of a serpent that are not
originally adjacent come to adjacent dimples (Figure C-2), they will
stick together and the serpent cannot but die. Two sections cannot
fit in one dimple, of course. This restricts serpents' moves
further. Sometimes, they have to make some efforts to get a food
piece even when it is in the dimple next to their head.
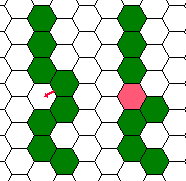
Figure C-2: Fatal case
Hexwamp has rocks here and there. Each rock fits in a dimple.
Hexerpents' skin does not stick to rocks, but they cannot crawl over
the rocks. Although avoiding dimples with rocks restricts their
moves, they know the geography so well that they can plan the fastest
paths.
You are appointed to take the responsibility of the head of the
scientist team to carry out academic research on this swamp and the
serpents. You are expected to accomplish the research, but never at
the sacrifice of any casualty. Your task now is to estimate how soon
a man-eating hexerpent may move its head (the first section) to the
position of a scientist in the swamp. Their body sections except for
the head are quite harmless and the scientist wearing high-tech
anti-sticking suit can stay in the same dimple with a body section of
the hexerpent.
Input
The input is a sequence of several datasets, and the end of the input
is indicated by a line containing a single zero. The number of
datasets never exceeds 10.
Each dataset looks like the following.
the number of sections the serpent has (=n)
x1 y1
x2 y2
...
xn yn
the number of rocks the swamp has (=k)
u1 v1
u2 v2
...
uk vk
X Y
The first line of the dataset has an integer
n that indicates
the number of sections the hexerpent has, which is 2 or greater and
never exceeds 8. Each of the
n following lines contains two
integers
x and
y that indicate the coordinates of a
serpent's section. The lines show the initial positions of the
sections from the serpent's head to its tail, in this order.
The next line of the dataset indicates the number of rocks k
the swamp has, which is a non-negative integer not exceeding 100.
Each of the k following lines contains two integers u
and v that indicate the position of a rock.
Finally comes a line containing two integers X and Y,
indicating the goal position of the hexerpent, where the scientist is.
The serpent's head is not initially here.
All of the coordinates x, y, u, v, X, and Y are between
−999999 and 999999, inclusive. Two integers in a line are
separated by a single space. No characters other than decimal digits,
minus signs, and spaces to separate two integers appear in the input.
The coordinate system used to indicate a position is as shown in
Figure C-3.
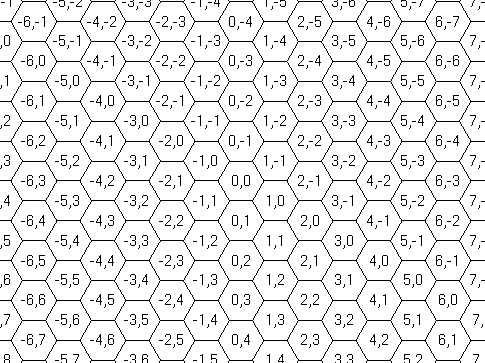
Figure C-3: The coordinate system
Output
For each dataset, output a line that contains a decimal integer that
indicates the minimum number of steps the serpent requires for moving
its head to the goal position. Output lines should not contain any
other characters.
You can assume that the hexerpent can reach the goal within 20 steps.
Sample Input
3
2 -2
2 -1
1 0
1
0 2
0 0
4
2 -2
2 -1
2 0
3 0
2
1 -1
0 2
0 0
8
-6 0
-5 0
-4 0
-3 0
-2 0
-1 0
0 0
1 0
1
-1 1
0 0
6
2 -3
3 -3
3 -2
3 -1
3 0
2 1
3
1 -1
1 0
1 1
0 0
3
-8000 4996
-8000 4997
-8000 4998
2
-7999 4999
-8001 5000
-8000 5000
8
10 -8
9 -7
9 -6
9 -5
9 -4
9 -3
9 -2
9 -1
0
0 0
0
Output for the Sample Input
Curling 2.0
On Planet MM-21, after their Olympic games this year, curling is getting popular.
But the rules are somewhat different from ours.
The game is played on an ice game board on which a square mesh is marked.
They use only a single stone.
The purpose of the game is to lead the stone from the start
to the goal with the minimum number of moves.
Fig. D-1 shows an example of a game board.
Some squares may be occupied with blocks.
There are two special squares namely the start and the goal,
which are not occupied with blocks.
(These two squares are distinct.)
Once the stone begins to move, it will proceed until it hits a block.
In order to bring the stone to the goal,
you may have to stop the stone by hitting it against a block,
and throw again.
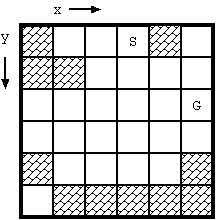
Fig. D-1: Example of board (S: start, G: goal)
The movement of the stone obeys the following rules:
- At the beginning, the stone stands still at the start square.
- The movements of the stone are restricted to x and y directions.
Diagonal moves are prohibited.
- When the stone stands still, you can make it moving by throwing it.
You may throw it to any direction
unless it is blocked immediately(Fig. D-2(a)).
- Once thrown, the stone keeps moving to the same direction until
one of the following occurs:
- The stone hits a block (Fig. D-2(b), (c)).
- The stone stops at the square next to the block it hit.
- The block disappears.
- The stone gets out of the board.
- The game ends in failure.
- The stone reaches the goal square.
- The stone stops there and the game ends in success.
- You cannot throw the stone more than 10 times in a game.
If the stone does not reach the goal in 10 moves, the game ends in failure.
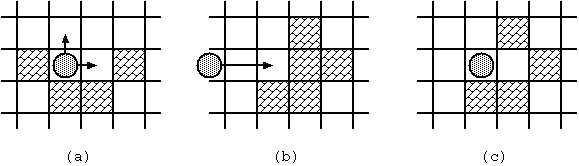
Fig. D-2: Stone movements
Under the rules, we would like to know whether the stone at the start
can reach the goal and, if yes, the minimum number of moves required.
With the initial configuration shown in Fig. D-1, 4 moves are required
to bring the stone from the start to the goal.
The route is shown in Fig. D-3(a).
Notice when the stone reaches the goal, the board configuration has changed
as in Fig. D-3(b).
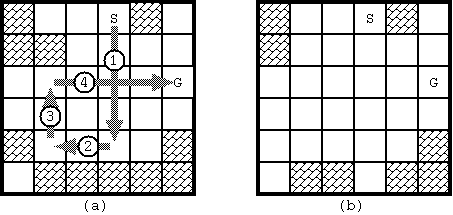
Fig. D-3: The solution for Fig. D-1 and the final board configuration
Input
The input is a sequence of datasets.
The end of the input is indicated by a line
containing two zeros separated by a space.
The number of datasets never exceeds 100.
Each dataset is formatted as follows.
the width(=w) and the height(=h) of the board
First row of the board
...
h-th row of the board
The width and the height of the board satisfy:
2 <=
w <= 20, 1 <=
h <= 20.
Each line consists of
w decimal numbers delimited by a space.
The number describes the status of the corresponding square.
| 0 | vacant square |
| 1 | block |
| 2 | start position |
| 3 | goal position |
The dataset for Fig. D-1 is as follows:
6 6
1 0 0 2 1 0
1 1 0 0 0 0
0 0 0 0 0 3
0 0 0 0 0 0
1 0 0 0 0 1
0 1 1 1 1 1
Output
For each dataset, print a line having a decimal integer indicating the
minimum number of moves along a route from the start to the goal.
If there are no such routes, print -1 instead.
Each line should not have any character other than
this number.
Sample Input
2 1
3 2
6 6
1 0 0 2 1 0
1 1 0 0 0 0
0 0 0 0 0 3
0 0 0 0 0 0
1 0 0 0 0 1
0 1 1 1 1 1
6 1
1 1 2 1 1 3
6 1
1 0 2 1 1 3
12 1
2 0 1 1 1 1 1 1 1 1 1 3
13 1
2 0 1 1 1 1 1 1 1 1 1 1 3
0 0
Output for the Sample Input
The Genome Database of All Space Life
In 2300, the Life Science Division of Federal Republic of Space starts
a very ambitious project to complete the genome sequencing of all
living creatures in the entire universe and develop the genomic
database of all space life.
Thanks to scientific research over many years, it has been known that
the genome of any species consists of at most 26 kinds of
molecules, denoted by English capital letters (i.e. A
to Z).
What will be stored into the database are plain strings consisting of
English capital letters.
In general, however, the genome sequences of space life include
frequent repetitions and can be awfully long.
So, for efficient utilization of storage, we compress N-times
repetitions of a letter sequence seq into
N(seq), where N is a natural
number greater than or equal to two and the length of seq is at
least one.
When seq consists of just one letter c, we may omit parentheses and write Nc.
For example, a fragment of a genome sequence:
ABABABABXYXYXYABABABABXYXYXYCCCCCCCCCC
can be compressed into:
4(AB)XYXYXYABABABABXYXYXYCCCCCCCCCC
by replacing the first occurrence of
ABABABAB with its compressed form.
Similarly, by replacing the following repetitions of
XY,
AB, and
C, we get:
4(AB)3(XY)4(AB)3(XY)10C
Since
C is a single letter, parentheses are omitted in this
compressed representation.
Finally, we have:
2(4(AB)3(XY))10C
by compressing the repetitions of
4(AB)3(XY).
As you may notice from this example, parentheses can be nested.
Your mission is to write a program that uncompress compressed genome
sequences.
Input
The input consists of multiple lines, each of which contains a
character string s and an integer i separated by a
single space.
The character string s, in the aforementioned manner,
represents a genome sequence.
You may assume that the length of s is between 1 and 100,
inclusive.
However, of course, the genome sequence represented by s may be
much, much, and much longer than 100.
You may also assume that each natural number in s representing the
number of repetitions is at most 1,000.
The integer i is at least zero and at most one million.
A line containing two zeros separated by a space follows the last input line and indicates
the end of the input.
Output
For each input line, your program should print a line containing the
i-th letter in the genome sequence that s represents.
If the genome sequence is too short to have the i-th element,
it should just print a zero.
No other characters should be printed in the output lines.
Note that in this problem the index number begins from zero rather
than one and therefore the initial letter of a sequence is its zeroth element.
Sample Input
ABC 3
ABC 0
2(4(AB)3(XY))10C 30
1000(1000(1000(1000(1000(1000(NM)))))) 999999
0 0
Output for the Sample Input
Secrets in Shadows
Long long ago, there were several identical columns (or
cylinders) built vertically in a big open space near Yokohama (Fig. F-1).
In the daytime, the shadows of the columns were moving on the
ground as the sun moves in the sky. Each column was
very tall so that its shadow was very long. The top view
of the shadows is shown in Fig. F-2.
The directions of the sun that minimizes and maximizes the
widths of the shadows of the columns were said to
give the important keys to the secrets of ancient treasures.

Fig. F-1: Columns (or cylinders)
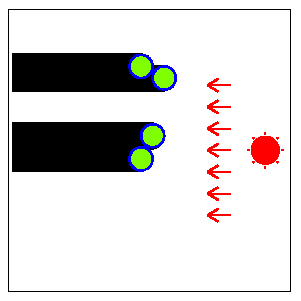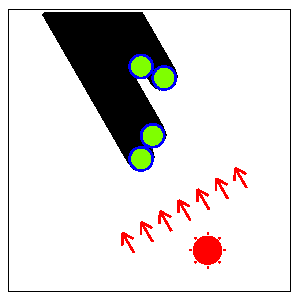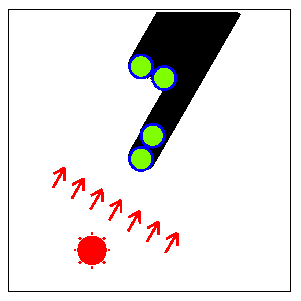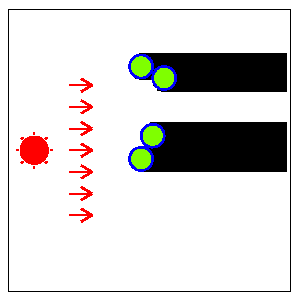
Fig. F-2: Top view of the columns (Fig. F-1) and their shadows
The width of the shadow of each column is the same as
the diameter of the base disk.
But the width of the whole shadow
(the union of the shadows of all the columns)
alters according to the direction of the sun
since the shadows of some columns may overlap those of other columns.
Fig. F-3 shows the direction of the sun that
minimizes the width of the whole shadow for
the arrangement of columns in Fig. F-2.
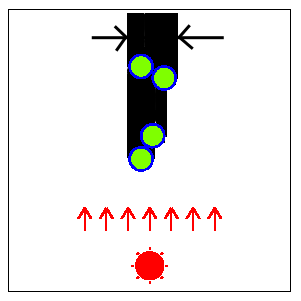
Fig. F-3: The direction of the sun for the minimal width of the whole shadow
Fig. F-4 shows the direction of the sun
that maximizes the width of the whole shadow.
When the whole shadow is separated into several parts (two
parts in this case), the width of the whole shadow is defined
as the sum of the widths of the parts.
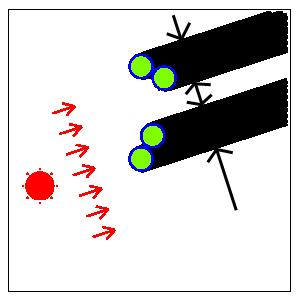
Fig. F-4: The direction of the sun for the maximal width of the whole shadow
A direction of the sun is specified by an angle θ
defined in Fig. F-5. For example, the east is
indicated by θ=0, the south by θ=π/2,
and the west by θ=π.
You may assume that the sun rises in the east (θ=0)
and sets in the west (θ=π).
Your job is to write a program that, given an arrangement of columns,
computes two
directions θmin and θmax
of the sun that give the minimal width and the maximal width of the
whole shadow, respectively.
The position of the center of the base disk of
each column is specified by its (x,y) coordinates.
The x-axis and y-axis are parallel to the
line between the east and the west and that between the north and the
south, respectively.
Their positive directions
indicate the east and the north, respectively.
You can assume that the big open space is a plane surface.
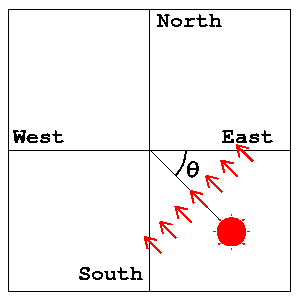
Fig. F-5: The definition of the angle of the direction of the sun
There may be more than one
θmin or θmax for some
arrangements in general,
but here, you may assume that we only consider
the arrangements that have unique
θmin and θmax in
the range 0<=θmin<π,
0<=θmax<π.
Input
The input consists of multiple datasets, followed by the last line
containing a single zero.
Each dataset is formatted as follows.
n
x1 y1
x2 y2
...
xn yn
n is the number of the columns in the big open space.
It is a positive integer no more than 100.
xk
and yk
are the values of
x-coordinate and y-coordinate
of the center of the base disk
of the k-th column (k=1, ..., n).
They are positive integers no more than 30.
They are separated by a space.
Note that the radius of the base disk of each column
is one unit (the diameter is two units).
You may assume that some columns may touch each other
but no columns overlap others.
For example, a dataset
3
1 1
3 1
4 3
corresponds to the arrangement of three columns depicted in Fig. F-6.
Two of them touch each other.
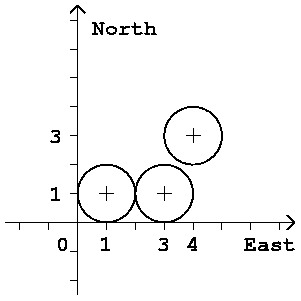
Fig. F-6: An arrangement of three columns
Output
For each dataset in the input, two lines should be output as
specified below.
The output lines should not contain extra characters such as spaces.
In the first line,
the angle θmin,
the direction of the sun giving the minimal width,
should be printed.
In the second line,
the other angle θmax,
the direction of the sun giving the maximal width,
should be printed.
Each angle should be contained in the
interval between 0 and π
(abbreviated to [0, π])
and
should not have an error greater than
ε=0.0000000001 (=10-10).
When the correct angle θ is in [0,ε],
approximate values
in [0,θ+ε] or
in [π+θ-ε, π] are accepted.
When the correct angle θ is in [π-ε, π],
approximate values
in [0, θ+ε-π] or
in [θ-ε, π] are accepted.
You may output any number of digits after the decimal point,
provided that the above accuracy condition is satisfied.
Sample Input
3
1 1
3 1
4 3
4
1 1
2 3
3 8
1 9
8
1 1
3 1
6 1
1 3
5 3
1 7
3 5
5 5
8
20 7
1 27
30 14
9 6
17 13
4 2
17 7
8 9
0
Output for the Sample Input
2.553590050042226
0.982793723247329
1.570796326794896
2.819842099193151
1.325817663668032
2.094395102393196
2.777613697080149
0.588002603547568