|
|
|
| Judgement data | |
Problem AIntegral RectanglesLet us consider rectangles whose height, h, and width, w, are both integers. We call such rectangles integral rectangles. In this problem, we consider only wide integral rectangles, i.e., those with w > h. We define the following ordering of wide integral rectangles. Given two wide integral rectangles,
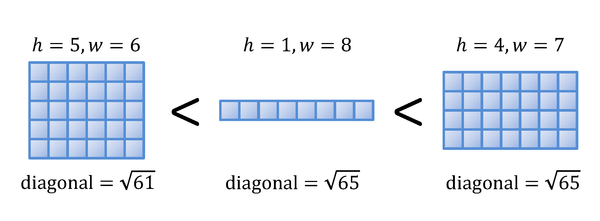
Given a wide integral rectangle, find the smallest wide integral rectangle bigger than the given one. InputThe entire input consists of multiple datasets. The number of datasets is no more than 100. Each dataset describes a wide integral rectangle by specifying its height and width, namely h and w, separated by a space in a line, as follows. h w For each dataset, h and w (>h) are both integers greater than 0 and no more than 100. The end of the input is indicated by a line of two zeros separated by a space. OutputFor each dataset, print in a line two numbers describing the height and width, namely h and w (> h), of the smallest wide integral rectangle bigger than the one described in the dataset. Put a space between the numbers. No other characters are allowed in the output. For any wide integral rectangle given in the input, the width and height of the smallest wide integral rectangle bigger than the given one are both known to be not greater than 150. In addition, although the ordering of wide integral rectangles uses the comparison of lengths of diagonal lines, this comparison can be replaced with that of squares (self-products) of lengths of diagonal lines, which can avoid unnecessary troubles possibly caused by the use of floating-point numbers. Sample Input1 2 1 3 2 3 1 4 2 4 5 6 1 8 4 7 98 100 99 100 0 0 Output for the Sample Input1 3 2 3 1 4 2 4 3 4 1 8 4 7 2 8 3 140 89 109 Problem BICPC RankingYour mission in this problem is to write a program which, given the submission log of an ICPC (International Collegiate Programming Contest), determines team rankings. The log is a sequence of records of program submission in the order of submission. A record has four fields: elapsed time, team number, problem number, and judgment. The elapsed time is the time elapsed from the beginning of the contest to the submission. The judgment field tells whether the submitted program was correct or incorrect, and when incorrect, what kind of an error was found. The team ranking is determined according to the following rules. Note that the rule set shown here is one used in the real ICPC World Finals and Regionals, with some detail rules omitted for simplification.
The total consumed time is the sum of the consumed time for each problem solved. The consumed time for a solved problem is the elapsed time of the accepted submission plus 20 penalty minutes for every previously rejected submission for that problem. If a team did not solve a problem, the consumed time for the problem is zero, and thus even if there are several incorrect submissions, no penalty is given. You can assume that a team never submits a program for a problem after the correct submission for the same problem. InputThe input is a sequence of datasets each in the following format. The last dataset is followed by a line with four zeros. M T P R The first line of a dataset contains four integers M, T, P, and R. M is the duration of the contest. T is the number of teams. P is the number of problems. R is the number of submission records. The relations 120 ≤ M ≤ 300, 1 ≤ T ≤ 50, 1 ≤ P ≤ 10, and 0 ≤ R ≤ 2000 hold for these values. Each team is assigned a team number between 1 and T, inclusive. Each problem is assigned a problem number between 1 and P, inclusive. Each of the following R lines contains a submission record with four integers mk, tk, pk, and jk (1 ≤ k ≤ R). mk is the elapsed time. tk is the team number. pk is the problem number. jk is the judgment (0 means correct, and other values mean incorrect). The relations 0 ≤ mk ≤ M−1, 1 ≤ tk ≤ T, 1 ≤ pk ≤ P, and 0 ≤ jk ≤ 10 hold for these values. The elapsed time fields are rounded off to the nearest minute. Submission records are given in the order of submission. Therefore, if i < j, the i-th submission is done before the j-th submission (mi ≤ mj). In some cases, you can determine the ranking of two teams with a difference less than a minute, by using this fact. However, such a fact is never used in the team ranking. Teams are ranked only using time information in minutes. OutputFor each dataset, your program should output team numbers (from 1 to T), higher ranked teams first. The separator between two team numbers should be a comma. When two teams are ranked the same, the separator between them should be an equal sign. Teams ranked the same should be listed in decreasing order of their team numbers. Sample Input300 10 8 5 50 5 2 1 70 5 2 0 75 1 1 0 100 3 1 0 150 3 2 0 240 5 5 7 50 1 1 0 60 2 2 0 70 2 3 0 90 1 3 0 120 3 5 0 140 4 1 0 150 2 4 1 180 3 5 4 15 2 2 1 20 2 2 1 25 2 2 0 60 1 1 0 120 5 5 4 15 5 4 1 20 5 4 0 40 1 1 0 40 2 2 0 120 2 3 4 30 1 1 0 40 2 1 0 50 2 2 0 60 1 2 0 120 3 3 2 0 1 1 0 1 2 2 0 300 5 8 0 0 0 0 0 Output for the Sample Input3,1,5,10=9=8=7=6=4=2 2,1,3,4,5 1,2,3 5=2=1,4=3 2=1 1,2,3 5=4=3=2=1 Problem CHierarchical DemocracyThe presidential election in Republic of Democratia is carried out through multiple stages as follows.
You can assume the following about the presidential election of this country.
This means that each district of every stage has its winner (there is no tie). Your mission is to write a program that finds a way to win the presidential election with the minimum number of votes. Suppose, for instance, that the district of the final stage has three sub-districts of the first stage and that the numbers of the eligible voters of the sub-districts are 123, 4567, and 89, respectively. The minimum number of votes required to be the winner is 107, that is, 62 from the first district and 45 from the third. In this case, even if the other candidate were given all the 4567 votes in the second district, s/he would inevitably be the loser. Although you might consider this election system unfair, you should accept it as a reality. InputThe entire input looks like: the number of datasets (=n) The number of datasets, n, is no more than 100. The number of the eligible voters of each district and the part-whole relations among districts are denoted as follows.
For instance, an electoral district of the first stage that has 123 eligible voters is denoted as [123]. A district of the second stage consisting of three sub-districts of the first stage that have 123, 4567, and 89 eligible voters, respectively, is denoted as [[123][4567][89]]. Each dataset is a line that contains the character string denoting the district of the final stage in the aforementioned notation. You can assume the following.
The number of stages is a nation-wide constant. So, for instance, [[[9][9][9]][9][9]] never appears in the input. [[[[9]]]] may not appear either since each district of the second or later stage must have multiple sub-districts of the previous stage. OutputFor each dataset, print the minimum number of votes required to be the winner of the presidential election in a line. No output line may include any characters except the digits with which the number is written. Sample Input6 [[123][4567][89]] [[5][3][7][3][9]] [[[99][59][63][85][51]][[1539][7995][467]][[51][57][79][99][3][91][59]]] [[[37][95][31][77][15]][[43][5][5][5][85]][[71][3][51][89][29]][[57][95][5][69][31]][[99][59][65][73][31]]] [[[[9][7][3]][[3][5][7]][[7][9][5]]][[[9][9][3]][[5][9][9]][[7][7][3]]][[[5][9][7]][[3][9][3]][[9][5][5]]]] [[8231][3721][203][3271][8843]] Output for the Sample Input107 7 175 95 21 3599 Problem DPrime CavesAn international expedition discovered abandoned Buddhist cave temples in a giant cliff standing on the middle of a desert. There were many small caves dug into halfway down the vertical cliff, which were aligned on square grids. The archaeologists in the expedition were excited by Buddha's statues in those caves. More excitingly, there were scrolls of Buddhism sutras (holy books) hidden in some of the caves. Those scrolls, which estimated to be written more than thousand years ago, were of immeasurable value. The leader of the expedition wanted to collect as many scrolls as possible. However, it was not easy to get into the caves as they were located in the middle of the cliff. The only way to enter a cave was to hang you from a helicopter. Once entered and explored a cave, you can climb down to one of the three caves under your cave; i.e., either the cave directly below your cave, the caves one left or right to the cave directly below your cave. This can be repeated for as many times as you want, and then you can descent down to the ground by using a long rope. So you can explore several caves in one attempt. But which caves you should visit? By examining the results of the preliminary attempts, a mathematician member of the expedition discovered that (1) the caves can be numbered from the central one, spiraling out as shown in Figure D-1; and (2) only those caves with their cave numbers being prime (let's call such caves prime caves), which are circled in the figure, store scrolls. From the next attempt, you would be able to maximize the number of prime caves to explore. 
Figure D-1: Numbering of the caves and the prime caves Write a program, given the total number of the caves and the cave visited first, that finds the descending route containing the maximum number of prime caves. InputThe input consists of multiple datasets. Each dataset has an integer m (1 ≤ m ≤ 106) and an integer n (1 ≤ n ≤ m) in one line, separated by a space. m represents the total number of caves. n represents the cave number of the cave from which you will start your exploration. The last dataset is followed by a line with two zeros. Output
For each dataset, find the path that starts from the cave n and
contains the largest number of prime caves, and output the number of
the prime caves on the path and the last prime cave number on the
path in one line, separated by a space. The cave n, explored first, is included
in the caves on the path.
If there is more than one such path, output for the path
in which the last of the prime caves explored has the largest number among such paths.
When there is no such path that explores prime caves, output " Sample Input49 22 46 37 42 23 945 561 1081 681 1056 452 1042 862 973 677 1000000 1000000 0 0 Output for the Sample Input0 0 6 43 1 23 20 829 18 947 10 947 13 947 23 947 534 993541 Problem EAnchored BalloonA balloon placed on the ground is connected to one or more anchors on the ground with ropes. Each rope is long enough to connect the balloon and the anchor. No two ropes cross each other. Figure E-1 shows such a situation. 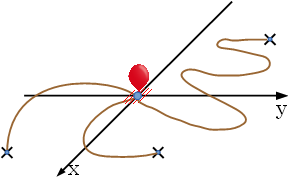
Figure E-1: A balloon and ropes on the ground Now the balloon takes off, and your task is to find how high the balloon can go up with keeping the rope connections. The positions of the anchors are fixed. The lengths of the ropes and the positions of the anchors are given. You may assume that these ropes have no weight and thus can be straightened up when pulled to whichever directions. Figure E-2 shows the highest position of the balloon for the situation shown in Figure E-1. 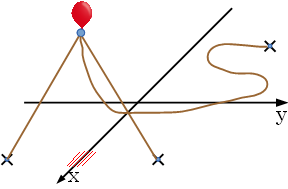
Figure E-2: The highest position of the balloon InputThe input consists of multiple datasets, each in the following format. n The first line of a dataset contains an integer n (1 ≤ n ≤ 10) representing the number of the ropes. Each of the following n lines contains three integers, xi, yi, and li, separated by a single space. Pi = (xi, yi) represents the position of the anchor connecting the i-th rope, and li represents the length of the rope. You can assume that −100 ≤ xi ≤ 100, −100 ≤ yi ≤ 100, and 1 ≤ li ≤ 300. The balloon is initially placed at (0, 0) on the ground. You can ignore the size of the balloon and the anchors. You can assume that Pi and Pj represent different positions if i ≠ j. You can also assume that the distance between Pi and (0, 0) is less than or equal to li−1. This means that the balloon can go up at least 1 unit high. Figures E-1 and E-2 correspond to the first dataset of Sample Input below. The end of the input is indicated by a line containing a zero. OutputFor each dataset, output a single line containing the maximum height that the balloon can go up. The error of the value should be no greater than 0.00001. No extra characters should appear in the output. Sample Input3 10 10 20 10 -10 20 -10 10 120 1 10 10 16 2 10 10 20 10 -10 20 2 100 0 101 -90 0 91 2 0 0 53 30 40 102 3 10 10 20 10 -10 20 -10 -10 20 3 1 5 13 5 -3 13 -3 -3 13 3 98 97 168 -82 -80 193 -99 -96 211 4 90 -100 160 -80 -80 150 90 80 150 80 80 245 4 85 -90 290 -80 -80 220 -85 90 145 85 90 170 5 0 0 4 3 0 5 -3 0 5 0 3 5 0 -3 5 10 95 -93 260 -86 96 211 91 90 177 -81 -80 124 -91 91 144 97 94 165 -90 -86 194 89 85 167 -93 -80 222 92 -84 218 0 Output for the Sample Input17.3205081 16.0000000 17.3205081 13.8011200 53.0000000 14.1421356 12.0000000 128.3928757 94.1879092 131.1240816 4.0000000 72.2251798 Problem FRotate and RewriteTwo sequences of integers A: A1 A2 ... An and B: B1 B2 ... Bm and a set of rewriting rules of the form "x1 x2 ... xk → y" are given. The following transformations on each of the sequences are allowed an arbitrary number of times in an arbitrary order independently.
Your task is to determine whether it is possible to transform the two sequences A and B into the same sequence. If possible, compute the length of the longest of the sequences after such a transformation. InputThe input consists of multiple datasets. Each dataset has the following form. n m r The first line of a dataset consists of three positive integers n, m, and r, where n (n ≤ 25) is the length of the sequence A, m (m ≤ 25) is the length of the sequence B, and r (r ≤ 60) is the number of rewriting rules. The second line contains n integers representing the n elements of A. The third line contains m integers representing the m elements of B. Each of the last r lines describes a rewriting rule in the following form. k x1 x2 ... xk y The first k is an integer (2 ≤ k ≤ 10), which is the length of the left-hand side of the rule. It is followed by k integers x1 x2 ... xk, representing the left-hand side of the rule. Finally comes an integer y, representing the right-hand side. All of A1, .., An, B1, ..., Bm, x1, ..., xk, and y are in the range between 1 and 30, inclusive. A line "0 0 0" denotes the end of the input. Output
For each dataset, if it is possible to transform A and B
to the same sequence, print the length of the longest of
the sequences after such a transformation.
Print Sample Input3 3 3 1 2 3 4 5 6 2 1 2 5 2 6 4 3 2 5 3 1 3 3 2 1 1 1 2 2 1 2 1 1 2 2 2 2 1 7 1 2 1 1 2 1 4 1 2 4 3 1 4 1 4 3 2 4 2 4 16 14 5 2 1 2 2 1 3 2 1 3 2 2 1 1 3 1 2 2 1 3 1 1 2 3 1 2 2 2 2 1 3 2 3 1 3 3 2 2 2 1 3 2 2 1 2 3 1 2 2 2 4 2 1 2 2 2 0 0 0 Output for the Sample Input2 -1 1 9 |
|