|
|
|
| 審判データ | |
Problem A整長方形高さhと幅wがともに整数である長方形を考えよう.そのような長方形を整長方形と呼ぶ.以下,この問題では横長の整長方形,すなわち w > h である整長方形のみを考える. 横長整長方形の大小関係を次のように定めよう.
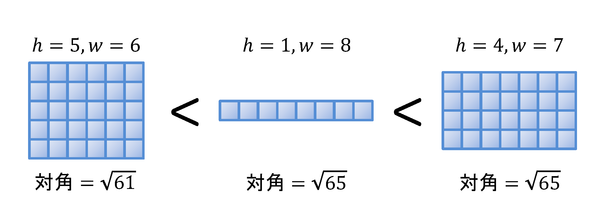
与えられた横長整長方形に対し,それより大きい最小の横長整長方形を求めよ. Input入力全体は複数のデータセットからなる.データセットの数は100以下である. 各データセットはひとつの横長整長方形を記述しており,その高さhと幅wがひとつの空白で区切られた以下のような1行である. h w 各データセットについて,hとw(>h)は,ともに,1以上100以下の整数である. 入力の終わりは,ひとつの空白で区切られたふたつの0から成る行によって示される. Output各データセットに対し,それに記述されている横長整長方形より大きい最小の横長整長方形の高さhと幅w (> h) とを,整数でひとつの空白文字で区切って1行に出力せよ.出力にはこれら以外の文字があってはならない. なお,この問題の入力で与えられる横長整長方形に対しては,それより大きい最小の横長整長方形の高さと幅はともに150を超えないことが分かっている. また,この問題では横長整長方形の大小を決めるために対角線の長さの大小比較を用いているが,これは対角線の長さの二乗の大小比較を用いても同じことであ る.対角線の長さの二乗の大小比較を用いることにより,浮動小数点計算の誤差によって生じうるトラブルを避けることができる. Sample Input1 2 1 3 2 3 1 4 2 4 5 6 1 8 4 7 98 100 99 100 0 0 Output for the Sample Input1 3 2 3 1 4 2 4 3 4 1 8 4 7 2 8 3 140 89 109 Problem BICPCの順位付けICPC (International Collegiate Programming Contest) の解答提出のログが与えられたとき, 各チームの順位を決定するプログラムを書きなさい. ログはプログラム提出の記録を提出順に並べたものである. 一つの記録は,経過時間,チーム番号,問題番号,判定結果, の四つの情報からなる. 経過時間は,コンテスト開始から提出までに要した時間を意味する. 判定結果は,プログラムが正解を出したか否か, また不正解だった場合の間違いの種類を表す. チームの順位は,次に示す規則に従って決められる. なお,この規則は,本物のICPCで使われている規則から 一部の細則を削除して簡単化したものである.
所要時間合計とは,正解した問題それぞれの所要時間の合計である. 問題の所要時間とは,その問題に正解したプログラム提出の経過時間に,それ以前に提出された同じ問題に対する不正解一つにつき20分ずつのペナルティを加えたものである. 正解に達しなかった問題の所要時間はゼロと見なされ,不正解がいくつあったとしても,ペナルティは発生しない. ある問題に正解した後に, 同じ問題に対するプログラムを提出することはないと仮定してよい. Input入力は,次の形式のデータセットの集まりである. 最後のデータセットの直後には,四つのゼロからなる行がある. M T P R データセットの最初の行には,M,T,P,Rの 四つの整数が与えられる. Mは,コンテストの始まりから終わりまでの時間である. Tは,チーム数である. Pは,問題数である. Rは,提出記録の数である. これらの値に関して, 120 ≤ M ≤ 300, 1 ≤ T ≤ 50, 1 ≤ P ≤ 10, 0 ≤ R ≤ 2000 が成り立つ. 各チームには1からTまでのチーム番号が与えられ, 各問題には1からPまでの問題番号が与えられている. 2行目からのR行に,1行一つの形式で提出記録が与えられる. 各提出記録の記述は, mk,tk, pk, jk の四つの整数からなる(1 ≤ k ≤ R). mkは,経過時間である. tkは,チーム番号である. pkは,問題番号である. jkは,判定結果を表す(0なら正解,0以外なら不正解). これらの値に関して, 0 ≤ mk ≤ M−1, 1 ≤ tk ≤ T, 1 ≤ pk ≤ P, 0 ≤ jk ≤ 10 が成り立つ. 経過時間は分単位に切り捨てられている. 提出記録は,提出された順番に従って与えられる. したがって,i < jなら, i番の提出はj番の提出より先に行われたものである (mi ≤ mj). このことを利用すると,二つのチームの所要時間合計の分未満の差の正負を 推定できる場合があるが, このような情報を順位決定に利用することはない. 各チームの順位は,分単位の時間情報だけに基づいて決める. Output各データセットに対して,1からTまでのチーム番号を 上位から順に1行に並べて出力しなさい. チーム番号間の区切り記号はコンマとする. ただし,同順位のチームの間の区切り記号はイコールとする. 同順位のチームは,チーム番号の大きいものから順に(降順に)並べること. Sample Input300 10 8 5 50 5 2 1 70 5 2 0 75 1 1 0 100 3 1 0 150 3 2 0 240 5 5 7 50 1 1 0 60 2 2 0 70 2 3 0 90 1 3 0 120 3 5 0 140 4 1 0 150 2 4 1 180 3 5 4 15 2 2 1 20 2 2 1 25 2 2 0 60 1 1 0 120 5 5 4 15 5 4 1 20 5 4 0 40 1 1 0 40 2 2 0 120 2 3 4 30 1 1 0 40 2 1 0 50 2 2 0 60 1 2 0 120 3 3 2 0 1 1 0 1 2 2 0 300 5 8 0 0 0 0 0 Output for the Sample Input3,1,5,10=9=8=7=6=4=2 2,1,3,4,5 1,2,3 5=2=1,4=3 2=1 1,2,3 5=4=3=2=1 Problem C階層民主主義デモクラティア共和国の大統領は,以下のような複数段階の選挙により選ばれる.
この国の大統領選挙では,以下の仮定が成り立つ.
したがって,すべての段階のすべての選挙区で,必ずどちらかの候補が勝つ (引き分けはない). あなたの仕事は,なるべく少ない得票数で大統領選挙に勝つ方法を求めるプログラムを作成することである. たとえば,最終段階の選挙区がちょうど三つの第1段階の選挙区を含んでおり,これらの第1段階の選挙区の有権者数がそれぞれ123名,4567名,89名だったとする. この場合,最初の選挙区で62票,3番目の選挙区で45票の計107票を獲得するのが,最も少ない得票数で勝つ方法になる. この場合,仮にもう一人の候補が2番目の選挙区で4567票すべてを獲得したとしても,敗者となることは避けられない. 不公平な選挙制度だと思うかもしれないが,これも現実として受け止めて欲しい. Input入力全体は以下の形式をしている. データセット数(=n) データセット数nは100以下である. 各選挙区の有権者数と選挙区同士の関係を次のような書式で記す.
たとえば,有権者数123名の第1段階の選挙区は,[123]と記される. また,有権者数がそれぞれ123名,4567名,89名の三つの第1段階の選挙区を含む第2段階の選挙区は,[[123][4567][89]]と記される. 各データセットは1行であり,この行は,最終段階の選挙区を上の書式で記した文字列よりなる. この問題を解くにあたり,次のように仮定して良い.
ステージの段数は国全体で一定である. したがって,たとえば,[[[9][9][9]][9][9]] は決して入力に現れない. また,[[[[9]]]] も現れない. なぜならば,第2段階以降の選挙区は,一つ前の段階の選挙区を必ず複数含むからである. Output各データセットに対し,最少得票数で大統領選挙に勝つために必要な票数を求め,それを1行に出力しなさい. 各出力行はこの数値以外の文字を含んではならない. Sample Input6 [[123][4567][89]] [[5][3][7][3][9]] [[[99][59][63][85][51]][[1539][7995][467]][[51][57][79][99][3][91][59]]] [[[37][95][31][77][15]][[43][5][5][5][85]][[71][3][51][89][29]][[57][95][5][69][31]][[99][59][65][73][31]]] [[[[9][7][3]][[3][5][7]][[7][9][5]]][[[9][9][3]][[5][9][9]][[7][7][3]]][[[5][9][7]][[3][9][3]][[9][5][5]]]] [[8231][3721][203][3271][8843]] Output for the Sample Input107 7 175 95 21 3599 Problem D素数洞穴砂漠の中の巨大な崖の中腹に,石窟寺院が残されているのを国際調査隊が発見しました.垂直にそびえ立つ崖のちょうど真ん中あたりに,無数の洞穴が縦横にき れいに並んでおり,それぞれの中に仏像が残されていたのです.さらにすごいことに,いくつかの洞穴には仏教の教典が隠されていました.千年以上も前に書か れたと見られる教典の価値は,それこそ計り知れません. 調査隊の隊長は,できるだけ多くの教典を持ち帰ることを決めました.ただ,洞穴は崖の中ほどにあるため,簡単には入れません.唯一の方法は,あなたの体を ヘリコプターで吊るして1つの洞穴に入って調査をし,その洞穴から縄を使ってすぐ下にある3つの洞穴(直下の洞穴か,直下の洞穴の右または左に隣り合う洞 穴)のどれかに降りるということを繰り返して降りてくるというものです.最後の洞穴からは長い縄を使って地面に降りることができます. 一度に何個かの洞穴を調査できるとは言うものの,どの洞穴を調査すればよいのでしょうか? そんな折,数学者のメンバーが予備調査の結果から教典が隠された洞穴にはある規則性があることを見つけました.彼によれば(1)洞穴には,中央のものに1 番,そこから図D-1のように外向きに渦を巻くように番号を付けると,(2)教典が隠されているのは図中丸で囲まれているような素数番目の洞穴(以降素数洞穴と呼びます)に他ならない,というのです.次回からはあなたが最初の洞穴に入ったら,素数洞穴を最も多く調査するように降りてくることができるでしょう. 
図D-1: 洞穴の番号と素数洞穴 洞穴の総数と最初に入る洞穴の番号が与えられたときに,素数洞穴をできるだけ多く調査できる降下経路を見つけるプログラムを作ってください. Input入力は複数のデータセットからなる.1つのデータセットは整数 m (1 ≤ m ≤ 106)と n (1 ≤ n ≤ m)を空白で区切った1行である.m は洞穴の総数を表し,n は最初に入る洞穴の番号を表す.最後のデータセットの次の行には2つのゼロが書かれている. Output
各データセットについて,洞穴 n から始めて,最も多く素数洞穴を調査する経路について,素数洞穴の個数と経路上最後に通過した素数洞穴の番号を空白で区切って1行に出力せよ.ただし最初に入る洞穴nも経路上の洞穴に含める.最も多くの素数洞穴を調査する経路が複数ある場合は,最後に通過した素数洞穴の番号が最も大きい経路について出力せよ.素数洞穴を調査する経路が1つもない場合には" Sample Input49 22 46 37 42 23 945 561 1081 681 1056 452 1042 862 973 677 1000000 1000000 0 0 Output for the Sample Input0 0 6 43 1 23 20 829 18 947 10 947 13 947 23 947 534 993541 Problem Eつながれた風船地面上に風船があり,地面上の1つ以上の杭とロープでつながれている. 各ロープは,風船と杭をつなぐのに十分な長さがある. ロープ同士は交差していない. 図 E-1 は,そのような状況を示したものである. 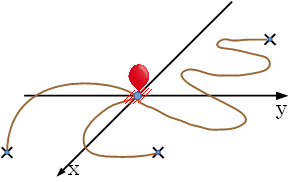
図E-1: 地面上にある風船とロープ 今,風船が飛びはじめた. あなたの仕事は,風船がロープの接続を維持したまま, どこまで高く飛ぶことができるか答えることである. 杭の位置は,固定されている. ロープの長さと,杭の位置は与えられる. また,ロープに重さはなく,どの方向に引っ張られたとしても, 一直線になりうると考えてよい. 図E-2は,図E-1の状態から風船が飛びはじめた時に, 風船が一番高くあがった位置を表している. 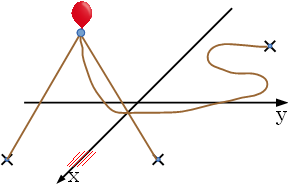
図E-2: 風船が一番高くあがった位置 Input入力は複数のデータセットからなり, 各データセットは次の形式で表される. n データセットの最初の行は,ロープの本数を表す整数 n (1 ≤ n ≤ 10) のみからなる. 続く n 行のそれぞれは,空白文字 1 個で区切られた 3 個の整数 xi, yi, li からなる. Pi = (xi, yi) は, i 番目のロープをつなぐ杭の位置を表し, li はそのロープの長さを表す. −100 ≤ xi ≤ 100, −100 ≤ yi ≤ 100, 1 ≤ li ≤ 300 であると仮定してよい. また,風船は,最初,地面上の (0, 0) に位置している. 風船および杭のサイズは無視してよい. PiとPj (i ≠ j) は異なる位置を表すものとする. また,Piから (0, 0) への距離は,li−1 以下であると仮定してよい. このため,風船は少なくとも高さ1まで飛ぶことができる. 図 E-1 と E-2 は,後に示す Sample Input 中の最初のデータセットに対応している. 入力の終わりは,ゼロを一つだけ含む行で表される. Output各データセットに対して,風船が飛ぶことのできる最大の高さを 1 行で出力せよ. 答えには 0.00001 を超える誤差があってはいけない. それ以外の余計な文字を出力してはならない. Sample Input3 10 10 20 10 -10 20 -10 10 120 1 10 10 16 2 10 10 20 10 -10 20 2 100 0 101 -90 0 91 2 0 0 53 30 40 102 3 10 10 20 10 -10 20 -10 -10 20 3 1 5 13 5 -3 13 -3 -3 13 3 98 97 168 -82 -80 193 -99 -96 211 4 90 -100 160 -80 -80 150 90 80 150 80 80 245 4 85 -90 290 -80 -80 220 -85 90 145 85 90 170 5 0 0 4 3 0 5 -3 0 5 0 3 5 0 -3 5 10 95 -93 260 -86 96 211 91 90 177 -81 -80 124 -91 91 144 97 94 165 -90 -86 194 89 85 167 -93 -80 222 92 -84 218 0 Output for the Sample Input17.3205081 16.0000000 17.3205081 13.8011200 53.0000000 14.1421356 12.0000000 128.3928757 94.1879092 131.1240816 4.0000000 72.2251798 Problem F回転と書換整数の列 A: A1 A2 ... An と B: B1 B2 ... Bm および "x1 x2 ... xk → y" という形式の書き換えルールがいくつか与えられる. 二つの列に対して独立に以下の変換を,任意の順序で任意回繰り返すことができる.
これらの操作を繰り返すことで,A と B を全く同じ列に変形することができるかどうか判定せよ. できる場合は,そのような変形を施した後の列のうちで最長の列の長さを答えよ. Input入力は複数のデータセットからなり,各データセットは以下の形をしている. n m r データセットの最初の行は三つの正整数 n, m, r からなり, n (n ≤ 25) は列 A の長さ, m (m ≤ 25) は列 B の長さ, r (r ≤ 60) は書き換えルールの個数を表す. 次の行には n 個の整数があり,これが列 A の n 個の要素を表す. その次の行には m 個の整数があり,これが列 B の m 個の要素を表す. その次には r 行が以下の形式で続く.各行が一つの書き換えルールに対応する. k x1 x2 ... xk y 最初の整数 k (2 ≤ k ≤ 10) はルールの左辺の長さである. 次に来る k 個の整数 x1 x2 ... xk はルールの左辺を表す. 最後に来る整数 y はルールの右辺を表す. A1, .., An, B1, ..., Bm, x1, ..., xk, y はすべて 1 以上 30 以下である. "0 0 0" と書かれた行が入力の終わりを示す. Output
各データセットについて, 同じ列に変形できる場合は,
そのような変換を施した後の列のうちで最長のものの長さを出力せよ.
同じ列に変形できない場合は, Sample Input3 3 3 1 2 3 4 5 6 2 1 2 5 2 6 4 3 2 5 3 1 3 3 2 1 1 1 2 2 1 2 1 1 2 2 2 2 1 7 1 2 1 1 2 1 4 1 2 4 3 1 4 1 4 3 2 4 2 4 16 14 5 2 1 2 2 1 3 2 1 3 2 2 1 1 3 1 2 2 1 3 1 1 2 3 1 2 2 2 2 1 3 2 3 1 3 3 2 2 2 1 3 2 2 1 2 3 1 2 2 2 4 2 1 2 2 2 0 0 0 Output for the Sample Input2 -1 1 9 |
|