Links
Problem A
Entrance Examination
The International Competitive Programming College (ICPC) is famous for its research on competitive programming. Applicants to the college are required to take its entrance examination.
The successful applicants of the examination are chosen as follows.
- The score of any successful applicant is higher than that of any unsuccessful applicant.
- The number of successful applicants n must be between nmin and nmax, inclusive. We choose n within the specified range that maximizes the gap. Here, the gap means the difference between the lowest score of successful applicants and the highest score of unsuccessful applicants.
- When two or more candidates for n make exactly the same gap, use the greatest n among them.
Let's see the first couple of examples given in Sample Input below. In the first example, nmin and nmax are two and four, respectively, and there are five applicants whose scores are 100, 90, 82, 70, and 65. For n of two, three and four, the gaps will be 8, 12, and 5, respectively. We must choose three as n, because it maximizes the gap.
In the second example, nmin and nmax are two and four, respectively, and there are five applicants whose scores are 100, 90, 80, 75, and 65. For n of two, three and four, the gap will be 10, 5, and 10, respectively. Both two and four maximize the gap, and we must choose the greatest number, four.
You are requested to write a program that computes the number of successful applicants that satisfies the conditions.
Input
The input consists of multiple datasets. Each dataset is formatted as follows.
m nmin nmax
P1
P2
...
Pm
The first line of a dataset contains three integers separated by single spaces. m represents the number of applicants, nmin represents the minimum number of successful applicants, and nmax represents the maximum number of successful applicants. Each of the following m lines contains an integer Pi, which represents the score of each applicant. The scores are listed in descending order. These numbers satisfy 0 < nmin < nmax < m ≤ 200, 0 ≤ Pi ≤ 10000 (1 ≤ i ≤ m) and Pnmin > Pnmax+1. These ensure that there always exists an n satisfying the conditions.
The end of the input is represented by a line containing three zeros separated by single spaces.
Output
For each dataset, output the number of successful applicants in a line.
Sample Input
5 2 4 100 90 82 70 65 5 2 4 100 90 80 75 65 3 1 2 5000 4000 3000 4 2 3 10000 10000 8000 8000 4 2 3 10000 10000 10000 8000 5 2 3 100 80 68 60 45 0 0 0
Output for the Sample Input
3 4 2 2 3 2
Problem B
Short Phrase
A Short Phrase (aka. Tanku) is a fixed verse, inspired by Japanese poetry Tanka and Haiku. It is a sequence of words, each consisting of lowercase letters 'a' to 'z', and must satisfy the following condition:
(The Condition for a Short Phrase)
The sequence of words can be divided into five sections such that the total number of the letters in the word(s) of the first section is five, that of the second is seven, and those of the rest are five, seven, and seven, respectively.
The following is an example of a Short Phrase.
do the best and enjoy today at acm icpc
In this example, the sequence of the nine words can be divided into five sections (1) "do" and "the", (2) "best" and "and", (3) "enjoy", (4) "today" and "at", and (5) "acm" and "icpc" such that they have 5, 7, 5, 7, and 7 letters in this order, respectively. This surely satisfies the condition of a Short Phrase.
Now, Short Phrase Parnassus published by your company has received a lot of contributions. By an unfortunate accident, however, some irrelevant texts seem to be added at beginnings and ends of contributed Short Phrases. Your mission is to write a program that finds the Short Phrase from a sequence of words that may have an irrelevant prefix and/or a suffix.
Input
The input consists of multiple datasets, each in the following format.
n
w1
...
wn
Here, n is the number of words, which is a positive integer not exceeding 40; wi is the i-th word, consisting solely of lowercase letters from 'a' to 'z'. The length of each word is between 1 and 10, inclusive. You can assume that every dataset includes a Short Phrase.
The end of the input is indicated by a line with a single zero.
Output
For each dataset, output a single line containing i where the first word of the Short Phrase is wi. When multiple Short Phrases occur in the dataset, you should output the first one.
Sample Input
9 do the best and enjoy today at acm icpc 14 oh yes by far it is wow so bad to me you know hey 15 abcde fghijkl mnopq rstuvwx yzz abcde fghijkl mnopq rstuvwx yz abcde fghijkl mnopq rstuvwx yz 0
Output for the Sample Input
1 2 6
Problem C
ICPC Calculator
In mathematics, we usually specify the order of operations by using parentheses. For example, 7 × (3 + 2) always means multiplying 7 by the result of 3 + 2 and never means adding 2 to the result of 7 × 3. However, there are people who do not like parentheses. International Counter of Parentheses Council (ICPC) is attempting to make a notation without parentheses the world standard. They are always making studies of such no-parentheses notations.
Dr. Tsukuba, a member of ICPC, invented a new parenthesis-free notation.
In his notation, a single expression is represented by multiple
lines, each of which contains an addition operator (
As expressions may be arbitrarily nested,
we have to make it clear which operator is applied to which operands.
For that purpose, each of the expressions is given its nesting level.
The top level expression has the nesting level of 0.
When an expression of level n is an operator application,
its operands are expressions of level n + 1.
The first line of an expression starts with a sequence of periods (
For example, 2 + 3 in the regular mathematics is denoted as in Figure 1.
An operator can be applied to two or more operands.
Operators
+ .2 .3Figure 1: 2 + 3
* .2 .3 .4Figure 2: An expression multiplying 2, 3, and 4
* .+ ..2 ..3 ..4 .5Figure 3: (2 + 3 + 4) × 5
* .+ ..2 ..3 .4 .5Figure 4: (2 + 3) × 4 × 5
Your job is to write a program that computes the value of expressions written in Dr. Tsukuba's notation to help him.
Input
The input consists of multiple datasets. Each dataset starts with a line containing a positive integer n, followed by n lines denoting a single expression in Dr. Tsukuba's notation.
You may assume that, in the expressions given in the input, every integer comprises a single digit and that every expression has no more than nine integers. You may also assume that all the input expressions are valid in the Dr. Tsukuba's notation. The input contains no extra characters, such as spaces or empty lines.
The last dataset is immediately followed by a line with a single zero.
Output
For each dataset, output a single line containing an integer which is the value of the given expression.
Sample Input
1 9 4 + .1 .2 .3 9 + .0 .+ ..* ...1 ...* ....1 ....2 ..0 10 + .+ ..6 ..2 .+ ..1 ..* ...7 ...6 .3 0
Output for the Sample Input
9 6 2 54
Problem D
500-yen Saving
"500-yen Saving" is one of Japanese famous methods to save money. The method is quite simple; whenever you receive a 500-yen coin in your change of shopping, put the coin to your 500-yen saving box. Typically, you will find more than one million yen in your saving box in ten years.
Some Japanese people are addicted to the 500-yen saving. They try their best to collect 500-yen coins efficiently by using 1000-yen bills and some coins effectively in their purchasing. For example, you will give 1320 yen (one 1000-yen bill, three 100-yen coins and two 10-yen coins) to pay 817 yen, to receive one 500-yen coin (and three 1-yen coins) in the change.
A friend of yours is one of these 500-yen saving addicts. He is planning a sightseeing trip and wants to visit a number of souvenir shops along his way. He will visit souvenir shops one by one according to the trip plan. Every souvenir shop sells only one kind of souvenir goods, and he has the complete list of their prices. He wants to collect as many 500-yen coins as possible through buying at most one souvenir from a shop. On his departure, he will start with sufficiently many 1000-yen bills and no coins at all. The order of shops to visit cannot be changed. As far as he can collect the same number of 500-yen coins, he wants to cut his expenses as much as possible.
Let's say that he is visiting shops with their souvenir prices of 800 yen, 700 yen, 1600 yen, and 600 yen, in this order. He can collect at most two 500-yen coins spending 2900 yen, the least expenses to collect two 500-yen coins, in this case. After skipping the first shop, the way of spending 700-yen at the second shop is by handing over a 1000-yen bill and receiving three 100-yen coins. In the next shop, handing over one of these 100-yen coins and two 1000-yen bills for buying a 1600-yen souvenir will make him receive one 500-yen coin. In almost the same way, he can obtain another 500-yen coin at the last shop. He can also collect two 500-yen coins buying at the first shop, but his total expenditure will be at least 3000 yen because he needs to buy both the 1600-yen and 600-yen souvenirs in this case.
You are asked to make a program to help his collecting 500-yen coins during the trip. Receiving souvenirs' prices listed in the order of visiting the shops, your program is to find the maximum number of 500-yen coins that he can collect during his trip, and the minimum expenses needed for that number of 500-yen coins.
For shopping, he can use an arbitrary number of 1-yen, 5-yen, 10-yen, 50-yen, and 100-yen coins he has, and arbitrarily many 1000-yen bills. The shop always returns the exact change, i.e., the difference between the amount he hands over and the price of the souvenir. The shop has sufficient stock of coins and the change is always composed of the smallest possible number of 1-yen, 5-yen, 10-yen, 50-yen, 100-yen, and 500-yen coins and 1000-yen bills. He may use more money than the price of the souvenir, even if he can put the exact money, to obtain desired coins as change; buying a souvenir of 1000 yen, he can hand over one 1000-yen bill and five 100-yen coins and receive a 500-yen coin. Note that using too many coins does no good; handing over ten 100-yen coins and a 1000-yen bill for a souvenir of 1000 yen, he will receive a 1000-yen bill as the change, not two 500-yen coins.
Input
The input consists of at most 50 datasets, each in the following format.
n
p1
...
pn
n is the number of souvenir shops, which is a positive integer not greater than 100. pi is the price of the souvenir of the i-th souvenir shop. pi is a positive integer not greater than 5000.
The end of the input is indicated by a line with a single zero.
Output
For each dataset, print a line containing two integers c and s separated by a space. Here, c is the maximum number of 500-yen coins that he can get during his trip, and s is the minimum expenses that he need to pay to get c 500-yen coins.
Sample Input
4 800 700 1600 600 4 300 700 1600 600 4 300 700 1600 650 3 1000 2000 500 3 250 250 1000 4 1251 667 876 299 0
Output for the Sample Input
2 2900 3 2500 3 3250 1 500 3 1500 3 2217
Problem E
Deadlock Detection
In concurrent processing environments, a deadlock is an undesirable situation where two or more threads are mutually waiting for others to finish using some resources and cannot proceed further. Your task is to detect whether there is any possibility of deadlocks when multiple threads try to execute a given instruction sequence concurrently.
The instruction sequence consists of characters '
There are 10 shared resources called locks from L0 to L9.
A digit k is the instruction for acquiring the lock Lk.
After one of the threads acquires a lock Lk,
it is kept by the thread until it is released by the instruction '
Precisely speaking, the following steps are repeated until all threads finish.
- One thread that has not finished yet is chosen arbitrarily.
- The chosen thread tries to execute the next instruction that is not executed yet.
- If the next instruction is a digit k and the lock Lk is not kept by any thread, the thread executes the instruction k and acquires Lk.
- If the next instruction is a digit k and the lock Lk is already kept by some thread, the instruction k is not executed.
- If the next instruction is '
u ', the instruction is executed and all the locks currently kept by the thread are released.
After executing several steps, sometimes, it falls into the situation that the next instructions of all unfinished threads are for acquiring already kept locks. Once such a situation happens, no instruction will ever be executed no matter which thread is chosen. This situation is called a deadlock.
There are instruction sequences for which threads can never reach a deadlock regardless of the execution order. Such instruction sequences are called safe. Otherwise, in other words, if there exists one or more execution orders that lead to a deadlock, the execution sequence is called unsafe. Your task is to write a program that tells whether the given instruction sequence is safe or unsafe.
Input
The input consists of at most 50 datasets, each in the following format.
n
s
n is the length of the instruction sequence and s is a string representing the sequence.
n is a positive integer not exceeding 10,000.
Each character of s is either a digit ('
The end of the input is indicated by a line with a zero.
Output
For each dataset, if the given instruction sequence is safe, then print
Sample Input
11 01u12u0123u 6 01u10u 8 201u210u 9 01u12u20u 3 77u 12 9u8u845u954u 0
Output for the Sample Input
SAFE UNSAFE SAFE UNSAFE UNSAFE UNSAFE
The second input "
 →
→
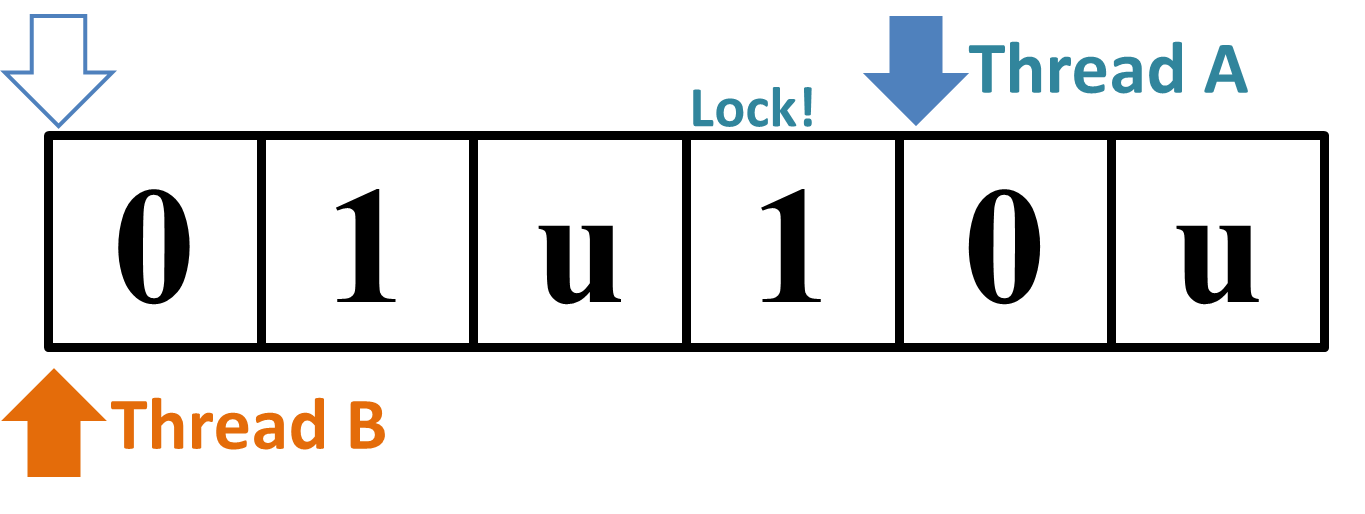 →
→
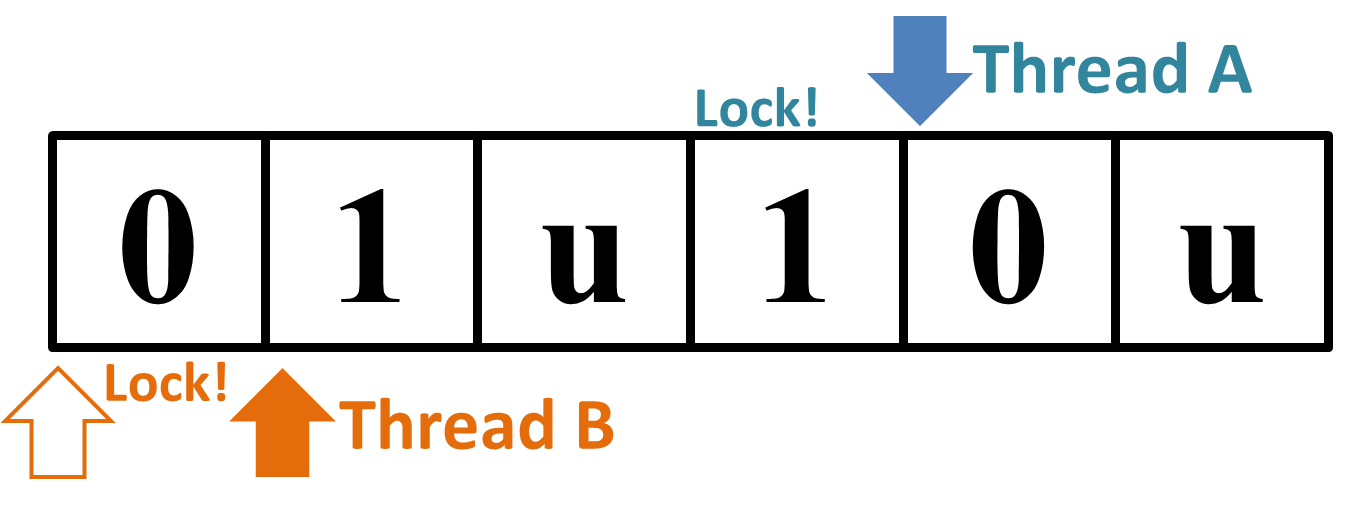
Figure 1: Why the Sample Input 2 "
Contrarily, the third input "
Problem F
Bridge Construction Planning
There is a city consisting of many small islands, and the citizens live in these islands. Citizens feel inconvenience in requiring ferry rides between these islands. The city mayor decided to build bridges connecting all the islands.
The city has two construction companies, A and B. The mayor requested these companies for proposals, and obtained proposals in the form: "Company A (or B) can build a bridge between islands u and v in w hundred million yen."
The mayor wants to accept some of these proposals to make a plan with the lowest budget. However, if the mayor accepts too many proposals of one company, the other may go bankrupt, which is not desirable for the city with only two construction companies. However, on the other hand, to avoid criticism on wasteful construction, the mayor can only accept the minimum number (i.e., n − 1) of bridges for connecting all the islands. Thus, the mayor made a decision that exactly k proposals by the company A and exactly n − 1 − k proposals by the company B should be accepted.
Your task is to write a program that computes the cost of the plan with the lowest budget that satisfies the constraints. Here, the cost of a plan means the sum of all the costs mentioned in the accepted proposals.
Input
The input consists of multiple datasets. The number of datasets is at most 30. Each dataset is in the following format.
n m k
u1 v1 w1 l1
...
um vm wm lm
The first line contains three integers n, m, and k, where n is the number of islands, m is the total number of proposals, and k is the number of proposals that are to be ordered to company A (2 ≤ n ≤ 200, 1 ≤ m ≤ 600, and 0 ≤ k ≤ n−1). Islands are identified by integers, 1 through n. The following m lines denote the proposals each of which is described with three integers ui, vi, wi and one character li, where ui and vi denote two bridged islands, wi is the cost of the bridge (in hundred million yen), and li is the name of the company that submits this proposal (1 ≤ ui ≤ n, 1 ≤ vi ≤ n, 1 ≤ wi ≤ 100, and li = 'A' or 'B'). You can assume that each bridge connects distinct islands, i.e., ui ≠ vi, and each company gives at most one proposal for each pair of islands, i.e., {ui, vi} ≠ {uj, vj} if i ≠ j and li = lj.
The end of the input is indicated by a line with three zeros separated by single spaces.
Output
For each dataset, output a single line containing a single integer that denotes the cost (in hundred million yen) of the plan with the lowest budget. If there are no plans that satisfy the constraints, output −1.
Sample Input
4 5 2 1 2 2 A 1 3 2 A 1 4 2 A 2 3 1 B 3 4 1 B 5 8 2 1 2 1 A 2 3 1 A 3 4 3 A 4 5 3 A 1 2 5 B 2 3 5 B 3 4 8 B 4 5 8 B 5 5 1 1 2 1 A 2 3 1 A 3 4 1 A 4 5 1 B 3 5 1 B 4 5 3 1 2 2 A 2 4 3 B 3 4 4 B 2 3 5 A 3 1 6 A 0 0 0
Output for the Sample Input
5 16 -1 -1
Problem G
Complex Paper Folding
Dr. G, an authority in paper folding and one of the directors of Intercultural Consortium on Paper Crafts, believes complexity gives figures beauty. As one of his assistants, your job is to find the way to fold a paper to obtain the most complex figure. Dr. G defines the complexity of a figure by the number of vertices. With the same number of vertices, one with longer perimeter is more complex. To simplify the problem, we consider papers with convex polygon in their shapes and folding them only once. Each paper should be folded so that one of its vertices exactly lies on top of another vertex.
Write a program that, for each given convex polygon, outputs the perimeter of the most complex polygon obtained by folding it once.
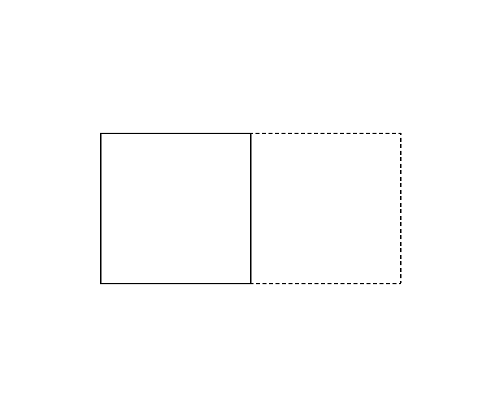
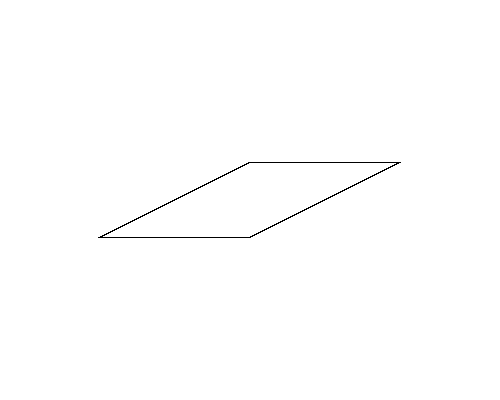
Figure 1 (left) illustrates the polygon given in the first dataset of Sample Input. This happens to be a rectangle. Folding this rectangle can yield three different polygons illustrated in the Figures 1-a to c by solid lines. For this dataset, you should answer the perimeter of the pentagon shown in Figure 1-a. Though the rectangle in Figure 1-b has longer perimeter, the number of vertices takes priority.
 |
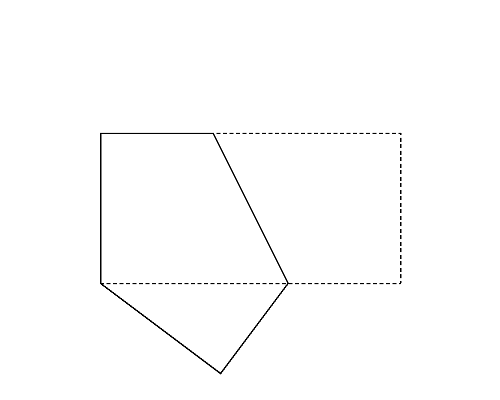 |
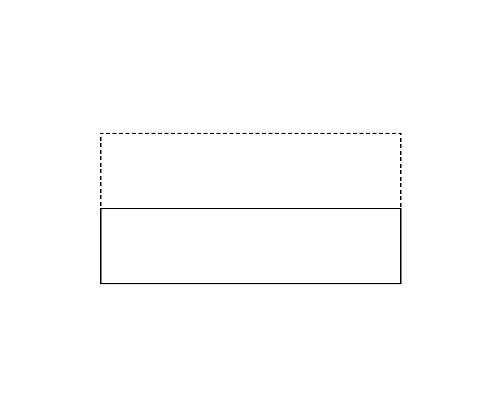 |
 |
| (a) | (b) | (c) |
Figure 1: The case of the first sample input
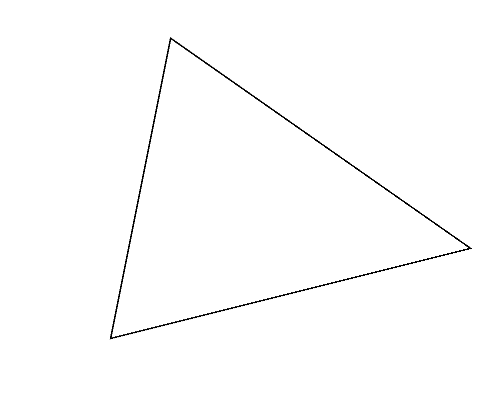
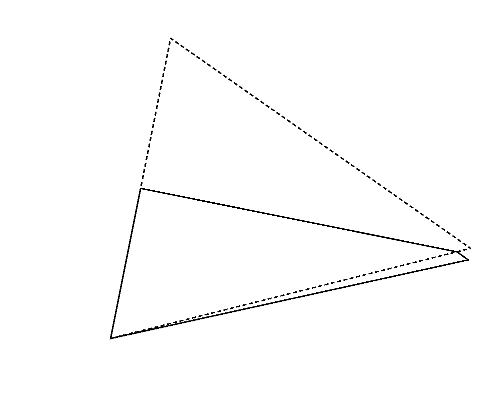
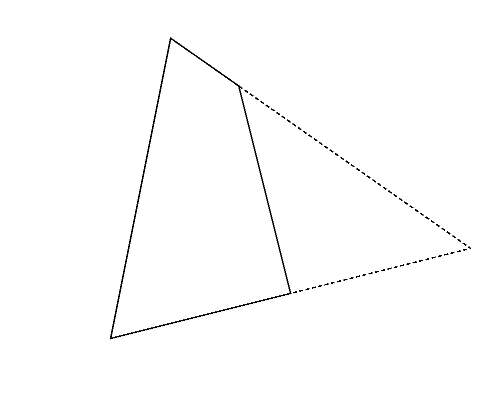
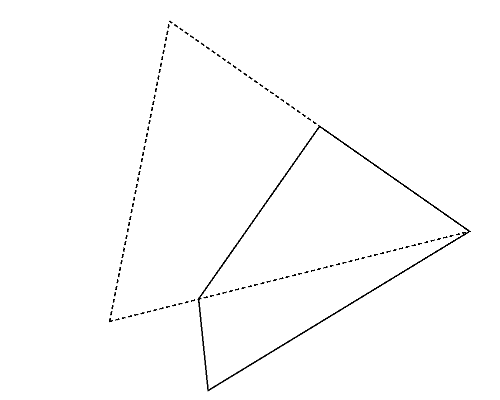
Figure 2 (left) illustrates the polygon given in the second dataset of Sample Input, which is a triangle. Whichever pair of its vertices are chosen, quadrangles are obtained as shown in Figures 2-a to c. Among these, you should answer the longest perimeter, which is that of the quadrangle shown in Figure 2-a.
 |
 |
 |
 |
| (a) | (b) | (c) |
Figure 2: The case of the second sample input
Although we start with a convex polygon, folding it may result a concave polygon. Figure 3 (left) illustrates the polygon given in the third dataset in Sample Input. A concave hexagon shown in Figure 3 (right) can be obtained by folding it, which has the largest number of vertices.
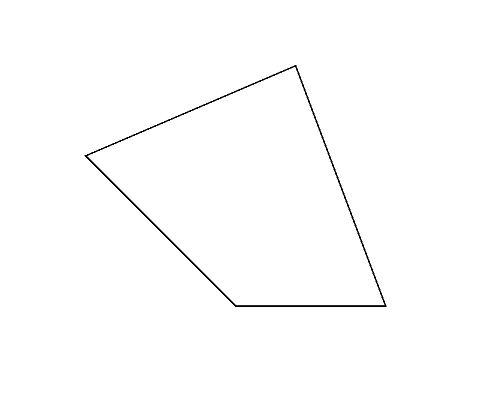
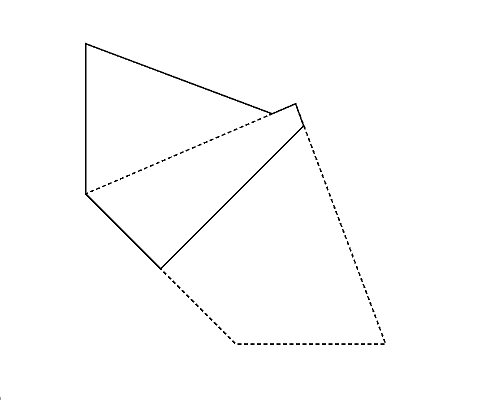
Figure 3: The case of the third sample input
Figure 4 (left) illustrates the polygon given in the fifth dataset in Sample Input. Although the perimeter of the polygon in Figure 4-b is longer than that of the polygon in Figure 4-a, because the polygon in Figure 4-b is a quadrangle, the answer should be the perimeter of the pentagon in Figure 4-a.
 |
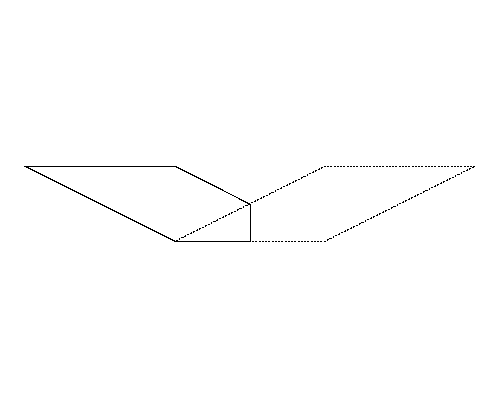 |
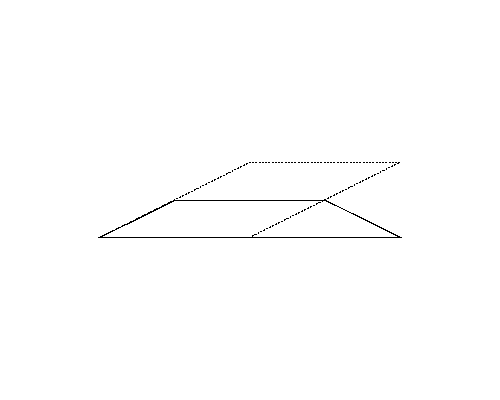 |
| (a) | (b) |
Figure 4: The case of the fifth sample input
Input
The input consists of multiple datasets, each in the following format.
n
x1 y1
...
xn yn
n is the number of vertices of the given polygon. n is a positive integer satisfying 3 ≤ n ≤ 20. (xi, yi) gives the coordinates of the i-th vertex. xi and yi are integers satisfying 0 ≤ xi, yi < 1000. The vertices (x1, y1), ..., (xn, yn) are given in the counterclockwise order on the xy-plane with y axis oriented upwards. You can assume that all the given polygons are convex.
All the possible polygons obtained by folding the given polygon satisfy the following conditions.
- Distance between any two vertices is greater than or equal to 0.00001.
- For any three consecutive vertices P, Q, and R, the distance between the point Q and the line passing through the points P and R is greater than or equal to 0.00001.
The end of the input is indicated by a line with a zero.
Output
For each dataset, output the perimeter of the most complex polygon obtained through folding the given polygon. The output value should not have an error greater than 0.00001. Any extra characters should not appear in the output.
Sample Input
4 0 0 10 0 10 5 0 5 3 5 0 17 3 7 10 4 0 5 5 0 10 0 7 8 4 0 0 40 0 50 5 0 5 4 0 0 10 0 20 5 10 5 7 4 0 20 0 24 1 22 10 2 10 0 6 0 4 18 728 997 117 996 14 988 1 908 0 428 2 98 6 54 30 28 106 2 746 1 979 17 997 25 998 185 999 573 999 938 995 973 970 993 910 995 6 0 40 0 30 10 0 20 0 40 70 30 70 0
Output for the Sample Input
23.090170 28.528295 23.553450 97.135255 34.270510 57.124116 3327.900180 142.111776
Problem H
Development of Small Flying Robots

You are developing small flying robots in your laboratory.
The laboratory is a box-shaped building with K levels, each numbered 1 through K from bottom to top. The floors of all levels are square-shaped with their edges precisely aligned east-west and north-south. Each floor is divided into R × R cells. We denote the cell on the z-th level in the x-th column from the west and the y-th row from the south as (x, y, z). (Here, x and y are one-based.) For each x, y, and z (z > 1), the cell (x, y, z) is located immediately above the cell (x, y, z − 1).
There are N robots flying in the laboratory, each numbered from 1 through N. Initially, the i-th robot is located at the cell (xi, yi, zi).
By your effort so far, you successfully implemented the feature to move each flying robot to any place that you planned. As the next step, you want to implement a new feature that gathers all the robots in some single cell with the lowest energy consumption, based on their current locations and the surrounding environment.
Floors of the level two and above have several holes. Holes are rectangular and their edges align with edges of the cells on the floors. There are M holes in the laboratory building, each numbered 1 through M. The j-th hole can be described by five integers u1j, v1j, u2j, v2j, and wj. The j-th hole extends over the cells (x, y, wj) where u1j ≤ x ≤ u2j and v1j ≤ y ≤ v2j.
Possible movements of robots and energy consumption involved are as follows.
- You can move a robot from one cell to an adjacent cell, toward one of north, south, east, or west. The robot consumes its energy by 1 for this move.
- If there is a hole to go through immediately above, you can move the robot upward by a single level. The robot consumes its energy by 100 for this move.
Input
The input consists of at most 32 datasets, each in the following format. Every value in the input is an integer.
N
M K R
x1 y1 z1
...
xN yN zN
u11 v11 u21 v21 w1
...
u1M v1M u2M v2M wM
N is the number of robots in the laboratory (1 ≤ N ≤ 100). M is the number of holes (1 ≤ M ≤ 50), K is the number of levels (2 ≤ K ≤ 10), and R is the number of cells in one row and also one column on a single floor (3 ≤ R ≤ 1,000,000).
For each i, integers xi, yi, and zi represent the cell that the i-th robot initially located at (1 ≤ xi ≤ R, 1 ≤ yi ≤ R, 1 ≤ zi ≤ K). Further, for each j, integers u1j, v1j, u2j, v2j, and wj describe the position and the extent of the j-th hole (1 ≤ u1j ≤ u2j ≤ R, 1 ≤ v1j ≤ v2j ≤ R, 2 ≤ wj ≤ K).
The following are guaranteed.- In each level higher than or equal to two, there exists at least one hole.
- In each level, there exists at least one cell not belonging to any holes.
- No two holes overlap. That is, each cell belongs to at most one hole.
The end of the input is indicated by a line with a single zero.
Output
For each dataset, print the minimum total energy consumption in a single line.
Sample Input
2 1 2 8 1 1 1 8 8 1 3 3 3 3 2 3 3 2 3 1 1 2 1 1 2 1 1 2 1 1 1 1 2 1 2 1 2 2 2 1 2 1 2 2 2 3 100 100 50 1 1 50 3 100 1 100 100 3 1 1 1 100 2 5 6 7 60 11 11 1 11 51 1 51 11 1 51 51 1 31 31 1 11 11 51 51 2 11 11 51 51 3 11 11 51 51 4 11 11 51 51 5 18 1 54 42 6 1 43 59 60 7 5 6 4 9 5 5 3 1 1 1 1 9 1 9 1 1 9 9 1 3 3 7 7 4 4 4 6 6 2 1 1 2 2 3 1 8 2 9 3 8 1 9 2 3 8 8 9 9 3 5 10 5 50 3 40 1 29 13 2 39 28 1 50 50 1 25 30 5 3 5 10 10 2 11 11 14 14 2 15 15 20 23 2 40 40 41 50 2 1 49 3 50 2 30 30 50 50 3 1 1 10 10 4 1 30 1 50 5 20 30 20 50 5 40 30 40 50 5 15 2 2 1000000 514898 704203 1 743530 769450 1 202298 424059 1 803485 898125 1 271735 512227 1 442644 980009 1 444735 799591 1 474132 623298 1 67459 184056 1 467347 302466 1 477265 160425 2 425470 102631 2 547058 210758 2 52246 779950 2 291896 907904 2 480318 350180 768473 486661 2 776214 135749 872708 799857 2 0
Output for the Sample Input
216 6 497 3181 1365 1930 6485356